A new economic model is taking shape
The Internet is being reprogrammed. This report is your field guide to what comes next.
Cloudflare serves over 93 million HTTP requests per second on average (more than 126 million at peak), and consistently processes approximately 85 million DNS queries per second — around 7.4 trillion queries per day. Our network spans 330+ cities across 200+ countries. We see traffic from the largest hyperscalers to the smallest independent publishers. We see crawlers that identify themselves honestly and shadow scrapers that do not. This is not aggregated from third-party sources or modeled from samples. This is what we observe directly at the application layer.
The data from Q1 2026 tells a story of rapid transition — from a human-centric Open Web to a machine-centric Programmable Web. AI is not the enemy of the web. It is the forcing function for a better deal.
AI crawler share reached 21.8% of verified bot traffic in Q1 2026. The question is no longer whether AI companies will pay for content — 50+ deals have been signed since 2023. The question is whether publishers have the tools to set the terms. That infrastructure exists now.
"The web is becoming programmable. That is not a threat — it is an opportunity for creators to define the terms on which their work powers the next generation of the Internet."
— Matthew Prince, CEO, CloudflareThe Great Divergence
The fundamental collapse is not hard to find in the data. The bot category breakdown tells the story of a web that has pivoted away from human utility:
Bot Traffic by Category — Q1 2026 vs Q4 2025
These percentages reflect the distribution of traffic among verified bots — a category that changes over time. Cloudflare's verified bot catalog grew from ~180 to 200+ bots between Q4 2025 and Q1 2026, including 37 AI crawlers and assistants. A category's share can shift because of traffic growth or because new bots were added to the verified catalog. For example, AI Crawler share grew from 17.5% to 21.8% — this reflects both organic traffic growth and the addition of newly verified AI crawlers to the dataset.
| Category | Q4 2025 | Q1 2026 | Change | Share |
|---|---|---|---|---|
| Search Engine Crawler | 36.3% | 31.1% | ▼ −5.2pp | |
| AI Crawler | 17.5% | 21.8% | ▲ +4.3pp | |
| SEO & Analytics | 12.2% | 13.3% | ▲ +1.1pp | |
| Advertising & Marketing | 13.0% | 10.6% | ▼ −2.4pp | |
| Page Preview | 6.6% | 6.6% | → flat | |
| Monitoring & Analytics | 3.6% | 3.7% | ▲ +0.1pp | |
| AI Search | 2.2% | 3.2% | ▲ +1.0pp | |
| Webhooks | 2.5% | 3.1% | ▲ +0.6pp | |
| Aggregator | 2.7% | 2.5% | ▼ −0.2pp |
The Top Bot Operators
Among individual bot operators, Google still commands 35.5% of all verified bot traffic — but its share dropped 6.2 percentage points QoQ. OpenAI is now the #3 bot operator among verified bots, at 9.5%, and growing.
AI Services Are Now Internet Infrastructure
One measure of how deeply AI has embedded itself in the Internet: ChatGPT is the #8 most-visited service globally, ahead of Amazon Shopping, TikTok, and Netflix. It is the #12 most-visited domain in the world.
Note: Lower rank number = higher traffic. Y-axis inverted. Source: Cloudflare Internet Services. Rankings are based on analysis of DNS resolver traffic (1.1.1.1), not on direct web traffic to the tools. Actual usage of the tools may differ from what DNS traffic analysis shows.
DeepSeek surged from #9–10 in the AI ranking to #4 in the single week of February 2, 2026 — immediately following global attention on DeepSeek-R1. A single model release can reshape the entire competitive landscape within days.
The Asymmetry of Extraction
"Training is done. Grounding is forever."
Models trained on your content six months ago have already learned from it. But every day, AI systems still need to ground their answers in fresh, accurate information. That ongoing dependency is your leverage. This is why blocking matters today — even if the training data is already in the models.
The core dysfunction of the current AI web is not that bots exist — it's that they consume without reciprocating. Among all AI bot crawl activity in Q1 2026:
89.3% of all AI crawler requests are extractive, consuming content to build models that may eventually route around the source entirely. Only 8.1% powers a search product that sends users back to original content.
The Individual Crawler Pecking Order
The individual crawler ranking reveals the precise hierarchy of extraction. These are the ten most active crawlers among Cloudflare's verified bot catalog, ranked by share of traffic from tracked verified bots:
| # | Crawler | Operator | % of Crawlers | Volume |
|---|---|---|---|---|
| 1 | Googlebot | 23.7% | ||
| 2 | GPTBot | OpenAI | 17.0% | |
| 3 | ClaudeBot | Anthropic | 14.4% | |
| 4 | Meta-ExternalAgent | Meta | 12.6% | |
| 5 | BingBot | Microsoft | 7.9% | |
| 6 | Amazonbot | Amazon | 5.3% | |
| 7 | FacebookExternalHit | Meta | 3.1% | |
| 8 | YandexBot | Yandex | 2.6% | |
| 9 | PetalBot | Huawei | 2.5% | |
| 10 | PerplexityBot | Perplexity | 1.8% |
Notable omissions from the top 10: DuckDuckGo's crawler operates primarily as a privacy-respecting search bot with minimal AI training overlap. xAI's GrokBot remains nascent in crawl volume despite xAI's growing profile — a gap likely to close as Grok integrates more deeply with X/Twitter's content graph.
GPTBot and ClaudeBot together account for 31.4% of tracked verified bot traffic — nearly a third of the crawler ecosystem in Cloudflare's verified catalog — yet the referral products attached to them remain nascent. They consume at the scale of Google; they return traffic at a fraction of it.
The Industry Heatmap: What AI Is Actually Consuming
Cloudflare data on AI bot vertical distribution reveals which industries are most exposed — and what kind of content they should be protecting.
What Each Vertical Should Protect
| Vertical | AI Crawl Share | Primary Content at Risk |
|---|---|---|
| Shopping & Retail | 31.1% | Product descriptions, pricing, imagery, reviews |
| Internet & Telecom | 16.7% | Infrastructure docs, API references, technical content |
| Computer & Electronics | 14.9% | Technical documentation, code, specs |
| News, Media & Publications | 9.2% | Articles, analysis, journalism — highest text quality per request |
| Business & Industry | 5.1% | B2B content, industry reports, market data |
| Travel & Tourism | 4.0% | Listings, reviews, itineraries, pricing |
| Finance | 2.9% | Market data, financial reporting, disclosures |
Shopping and retail is the most-crawled category at 31.1% — not because consumers are using AI to shop (yet), but because product data is rich training corpus for AI models that aim to assist with purchasing decisions. The crawl happens long before any agentic commerce product launches.
These vertical distributions reflect crawl activity observed across Cloudflare's customer base, which may not be evenly distributed across industries. If Cloudflare has an outsized share of e-commerce or retail customers (for example, via platforms like Shopify), that customer composition could skew the observed crawl distribution toward shopping and retail relative to the true distribution across the entire web.
News and Media accounts for 9.2% of AI crawl activity — a figure that understates the impact. A retail product description is one sentence. A news article is thousands of words of structured, fact-checked prose. The training value per crawl request is not equal.
The ability to credibly control access is what makes content a licensable asset. Publishers who can define who accesses their content, at what terms, and verify compliance — have something concrete to bring to a negotiation. Cloudflare's enforcement layer is what converts that capability from a policy statement into a technical reality.
The Hidden Tax of Crawling
Crawling is not just a strategic problem — it is a direct cost. Every page served to a bot that returns no referral traffic is bandwidth consumed, origin compute burned, and infrastructure fees accrued for zero commercial return. Consider a mid-sized publisher whose site is hit by a single undeclared bot requesting one million pages per month. At an average page weight of 1.5MB, that is 1.5 terabytes of data served for no audience growth, no ad revenue, and no licensing fee. At $0.005/GB for origin egress, that alone is $7,500 per month — $90,000 annually — for one bot. Add CDN overages, origin compute, logging, and security processing, and the real number climbs well into six figures. And most publishers are not dealing with one bot. They are dealing with dozens.
The cost compounds in ways that do not appear on a single line item. Server capacity diverted to bots is server capacity not available for real readers and buyers. The only way to stop this leakage is to block the crawlers that consume without reciprocating — particularly the undeclared and unverified bots that deliver no referral value and answer to no one. Publisher infrastructure was built for human audiences. When bots consume at human scale without human return, the economics break.
From Robots.txt to Honest Bot Detection
Publishers are responding with the only tool most of them have: a text file first implemented in the mid-1990s and codified as RFC 9309 in 2022. GPTBot and ClaudeBot are the most restricted crawlers in the robots.txt ecosystem. In Cloudflare's verified bot catalog, 37 of 200 tracked bots are now AI crawlers or AI assistants — a category that barely existed two years ago.
Why Robots.txt Is Not Enough
First: compliance is voluntary. Our AI crawl timeseries shows that AI bot traffic hit its single-day peak of Q1 2026 on February 9 — even as blocking rates have been rising throughout the quarter. Volume is growing faster than restrictions can contain it.
Second: shadow scrapers exist. Our data shows 0.44% of AI bot crawl activity comes from bots declaring no purpose — Undeclared crawlers operating without transparency. Some of these bots simply fail to declare their intent. Others deliberately misidentify themselves, wearing a Googlebot mask to crawl as if they have permission they have not sought.
Third: the past is already gone. Models trained on data crawled before publishers erected their defenses have already consumed that content. The window of prevention is partly closed.
Web Bot Auth: Cryptographic Verification
This is why Cloudflare built Web Bot Auth — a new cryptographic verification mechanism that uses signatures to verify a bot's identity at the protocol level. If a bot claims to be Googlebot, it signs its requests with a key only Google holds. If the signature fails, the claim is false. Web Bot Auth does not rely on bots choosing to be honest; it makes dishonesty technically detectable.
AI agents — bots that actively browse, fill forms, and execute tasks — are the fastest-growing category in Cloudflare's verified bot catalog. These agents cannot be managed with robots.txt alone. Cryptographic identity is the necessary infrastructure for the Programmable Web.
AI Search: A New Referral Ecosystem
This section covers bots classified as "AI Search" — crawlers attached to AI-powered search products that return traffic to original sources. It does not include mixed-purpose crawlers such as Googlebot, which serves both search indexing and AI training. Those dual-purpose crawlers are classified separately in the data.
The AI Search category — crawlers attached to AI-powered search products that do return traffic to original sources — is one of the most strategically important in the ecosystem. It grew 1.0 percentage point QoQ — the fastest-growing bot subcategory this quarter.
| Operator | Share of AI Search Traffic | Product |
|---|---|---|
| Apple | 58.8% | Applebot → Siri, Spotlight, Apple Intelligence |
| OpenAI | 41.0% | OAI-SearchBot → ChatGPT Search |
| Cloudflare | 0.13% | Cloudflare AI Search |
| Brave | 0.07% | Brave Search AI |
Apple is the dominant AI search crawler, driven by Applebot's role in powering Siri and Apple Intelligence. Apple's crawl activity was highly volatile in Q1 2026 — near zero on some days, spiking by late March — suggesting active product development. A company with 2.35 billion active devices and a first-party AI search product is a fundamentally different referral engine than anything that preceded it.
OAI-SearchBot spiked noticeably during peak AI news periods (Jan 22–24, Feb 9, Mar 10–11), suggesting its crawl intensity tracks closely with ChatGPT usage surges. As AI search products mature and publishers begin demanding referral as a condition of access, this is the category that matters most.
The AI Agent Layer: From Crawlers to Action
The most nascent but strategically significant development is the emergence of AI assistants as a distinct traffic category. These are not crawlers passively indexing content — they are agents actively executing tasks: browsing pages, filling forms, clicking buttons, completing purchases.
| Operator | Share of AI Assistant Traffic |
|---|---|
| OpenAI | 86.0% |
| Cloudflare (Browser Rendering) | 10.7% |
| DuckDuckGo | 2.5% |
| Mistral AI | 0.26% |
| Meta | 0.25% |
| Manus | 0.22% |
| Amazon | 0.03% |
| Devin AI | 0.03% |
The 21 verified AI assistant bots in our catalog include Amazon Bedrock AgentCore Browser (deployed across 9 AWS regions), Amazon's "Buy For Me" agent, Devin AI, CartAI, Apify, and Browserbase.
An agent that can complete a purchase on a user's behalf represents a new distribution channel — one where publishers and developers who establish the right integrations will be present at the moment of action, not just the moment of discovery. The shift from crawl-and-display to act-on-behalf creates new surfaces for attribution, licensing, and value exchange that do not exist in the search paradigm. Cloudflare is building infrastructure for this shift with WebMCP — bringing the Model Context Protocol to the browser, allowing AI agents to securely interact with websites through standardized tool-calling interfaces.
Bot Management: Cloudflare's Defense Layer
The data in this report — crawl volumes, intent classification, shadow scrapers, verified identities — doesn't surface without infrastructure. Cloudflare's Bot Management platform is the layer between publishers and the automated web, scoring every request with a bot probability, a purpose classification, and an enforcement decision. At the scale of 55 million requests per second — feeding our detection models, from tens of millions of domains, this is not a feature. It is the operating system of the Programmable Web.
AI Crawl Control: Publisher Enforcement at the Edge
The most consequential Bot Management capability for publishers in Q1 2026 is AI Crawl Control — purpose-built tooling for per-operator access policy on AI bots. Unlike robots.txt, which is a voluntary convention any bad actor can ignore, AI Crawl Control enforces access decisions at the network edge before content is ever served.
Cloudflare data shows AI crawl traffic hit its single-day peak of Q1 2026 on February 9 — even as publisher blocking rates have been rising throughout the quarter. The 0.44% of AI crawl traffic classified as "Undeclared" operates with no stated purpose — some simply fail to declare their intent; others deliberately misidentify themselves to evade publisher blocks. A text file on a server is not enforcement. Edge-level bot scoring is.
AI Crawl Control lets publishers set distinct rules per crawler identity — allowing OAI-SearchBot (which drives referral traffic) while blocking GPTBot (which trains models without reciprocation). Publishers can say, for the first time: you may index, but you may not train.
Shadow scrapers preferentially impersonate Googlebot — the one crawler virtually no publisher can afford to block. Web Bot Auth's cryptographic signature requirement closes this permanently: a crawler that cannot produce Google's private key cannot impersonate Googlebot.
Bot Score Distribution — Q1 2026
Cloudflare classifies >50% of web traffic as automated machines — the majority of the web is now machine-accessed.
| Bot Score | Classification | Recommended Action | Share of Traffic |
|---|---|---|---|
| 1–29 | Likely Bot | Block or challenge | 24.1% |
| 30–49 | Possibly Bot | Challenge with Turnstile | 2.8% |
| 50–79 | Ambiguous | Log, monitor, apply additional signals | 3.6% |
| 80–99 | Likely Human | Allow | 69.5% |
The /crawl Endpoint: Compliant Crawling by Design
Launched March 2026, the Browser Rendering /crawl endpoint is a developer API for RAG pipelines and training datasets — built as a compliant, permission-respecting crawler. It cryptographically identifies itself, respects robots.txt and AI Crawl Control settings, and cannot bypass detection. For publishers, the critical advantage is accountability: every /crawl request is tied to a known, identifiable operator rather than an anonymous scraper, giving them the same visibility and control over their traffic that they expect from any registered bot. Available on all plans.
From Defense to Access Control Infrastructure
Bot Management is no longer purely a security product. It is the access control layer for a new content economy. Granular identity enforcement at the edge makes tiered access possible: free for search, licensed for training, auditable for both. The deal is only as good as the infrastructure beneath it — and that infrastructure now exists.
The Attribution Dashboard: Your Negotiating Brief
The Attribution Overview turns bot management data into a deal-ready evidence base. For the first time, publishers have operator-level attribution data — the evidence base for licensing negotiations.
Bot View — Operator-Level Attribution
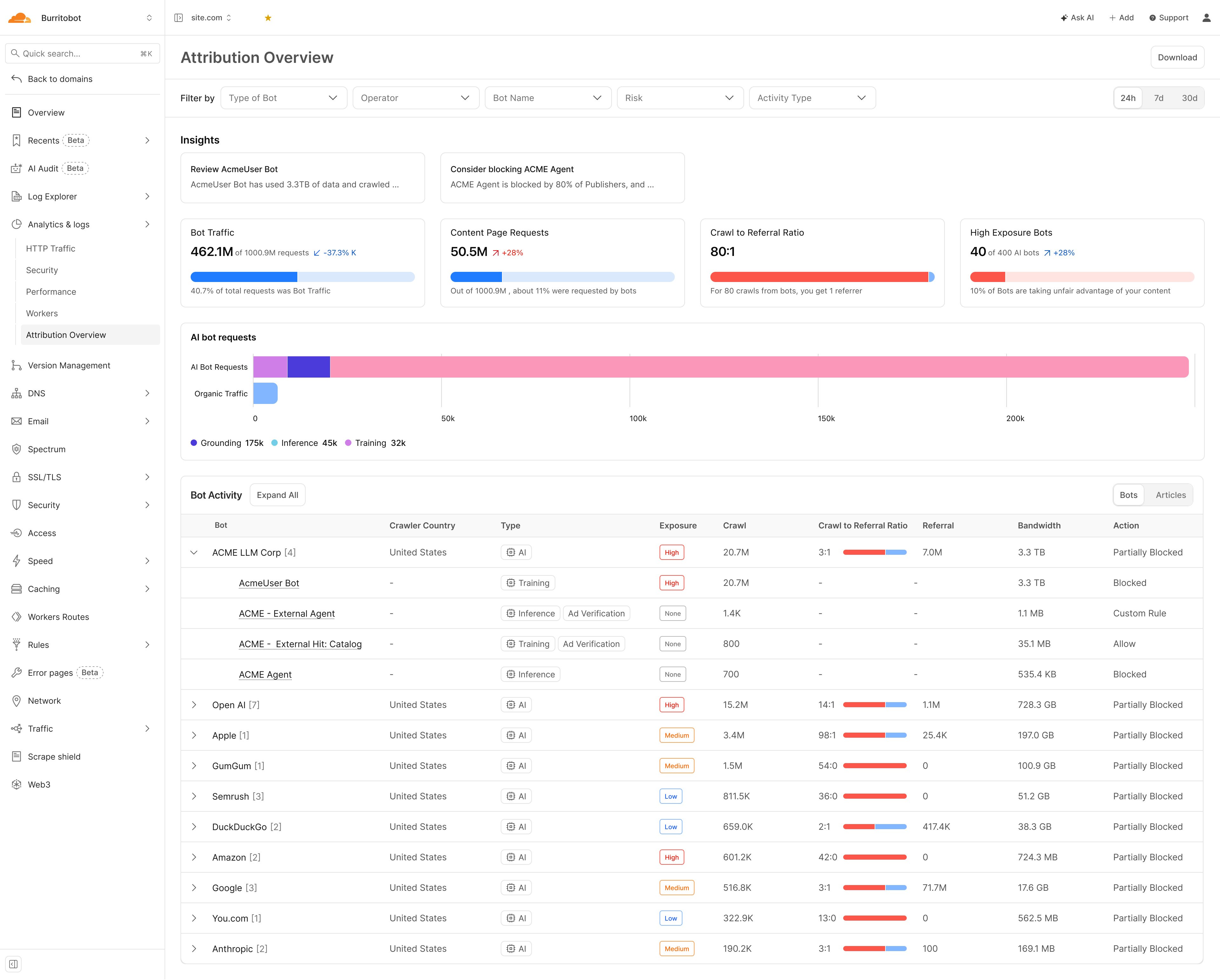
Quantifies extraction imbalance — how many AI crawl requests it takes to produce one human referral. An 80:1 ratio means taking 80x more than returned.
Classifies purpose per visit: Training (model building), Inference (query-time retrieval), or Grounding (factual anchoring). Each has different commercial value.
Consumption measured in gigabytes/terabytes — an established billing metric. Peer blocking intelligence shows what percentage of publishers have blocked each bot.
Articles View — Content-Level Attribution
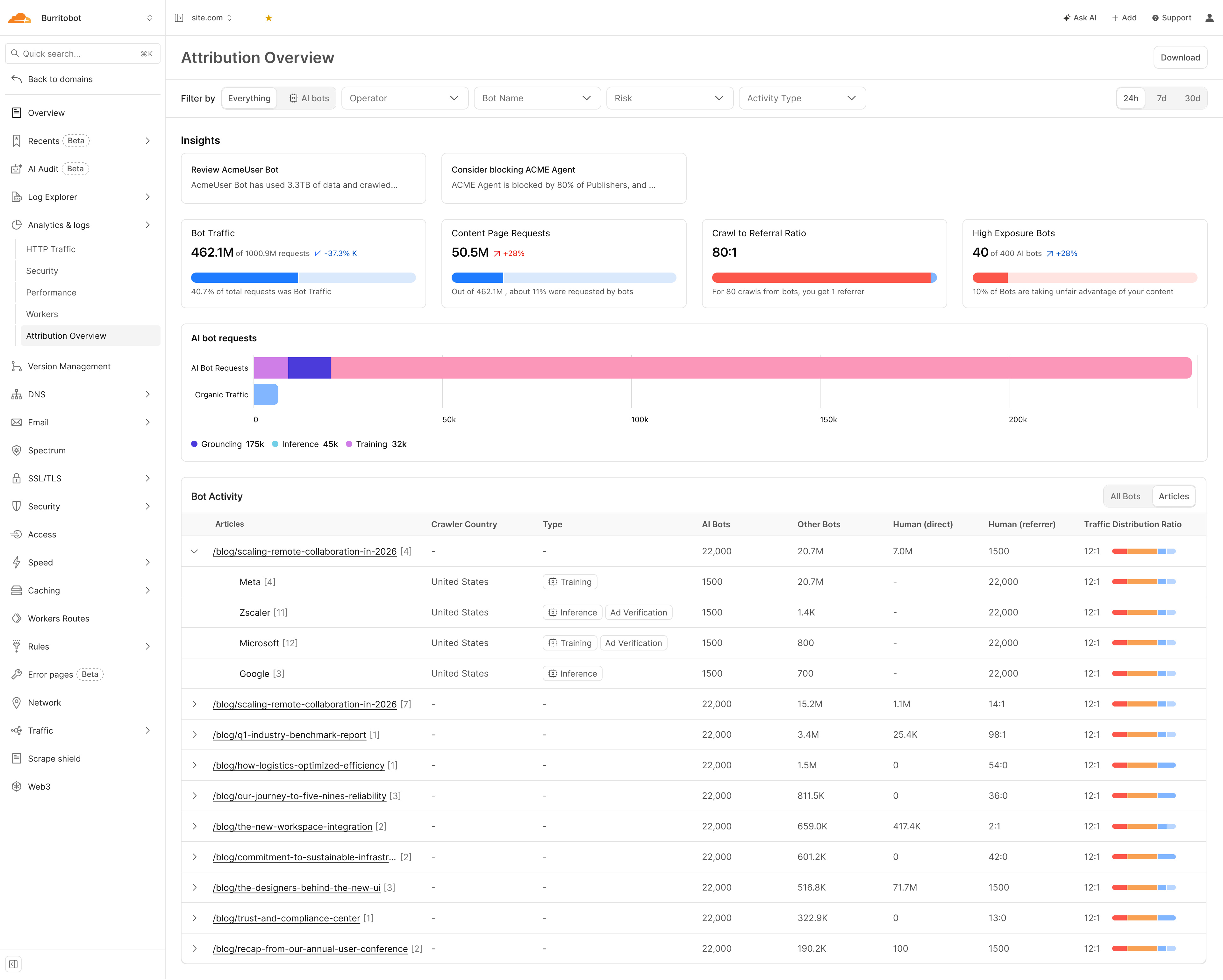
See which specific articles AI companies crawl, their intent, and AI-to-human traffic ratios. High AI-to-human ratio means content generates training data, not audience — a distinction with a price.
Once a deal is signed, the Articles view becomes the consumption metering layer — tracking what AI companies access, at what volume, with what intent, article by article.
Monetization: The Publisher-AI Deal Economy
The data has produced a market. Since the first publisher-AI deal in July 2023, a licensing economy has grown from a handful of bilateral experiments into 50+ documented agreements across OpenAI, Google, Perplexity, Microsoft, Meta, Amazon, Mistral, and Prorata — spanning wire services, national newspapers, magazines, specialist publishers, and collective licensing pools. Deal velocity slowed measurably in Q1 2026. After a flurry of announcements in 2024 and early 2025, the first quarter of 2026 saw fewer new signings — not because demand cooled, but because the easy deals are done. Publishers are now negotiating harder, demanding attribution guarantees, usage audits, and exit clauses. The market is shifting from land-grab to terms.
"We are very happy with either model — both can be viable as long as our content is respected and paid for."
— Neil Vogel, CEO, People Inc. (Dotdash Meredith)Publisher-AI Deals by AI Company
A summary of confirmed publisher-AI content licensing deals, aggregated by AI platform. Covers training data licences, RAG/retrieval integrations, revenue-share programs, and platform-specific content marketplaces. This is not an exhaustive list — deal terms are often undisclosed, and new agreements are announced regularly.
| AI Company | # of Deals + Publisher Names |
|---|---|
| OpenAI | 18 deals — Associated Press, Axel Springer, Le Monde, Prisa Media, Financial Times, Dotdash Meredith, News Corp, The Atlantic, Vox Media, TIME, Condé Nast, Hearst, Washington Post, Axios, The Guardian, Schibsted, Future plc, Lee Enterprises |
| 2 deals — Associated Press, The Guardian, Washington Post, FT, Der Spiegel (pilot program) | |
| Perplexity | 4 deals — TIME, Der Spiegel, Fortune, Entrepreneur, The Texas Tribune, Automattic, The Independent, LA Times, Lee Enterprises, Adweek, Blavity, DPReview, Gear Patrol, MediaLab, Mexico News Daily, Minkabu Infonoid, NewsPicks, NTV, Prisa Media, Stern, Gannett / USA Today Co., Getty Images |
| Microsoft | 5 deals — Axel Springer, Informa, FT, Reuters, Hearst, USA Today Network, People Inc., Associated Press |
| Meta | 3 deals — Reuters, CNN, Fox News, Fox Sports, Le Monde Group, People Inc., The Daily Caller, The Washington Examiner, USA Today, News Corp |
| Amazon | 4 deals — New York Times, Condé Nast, Hearst, Reach |
| Prorata | 5 deals — Financial Times, Axel Springer, The Atlantic, Fortune, DMG Media, Sky News, The Guardian, Prospect, Lee Enterprises, News/Media Alliance members, 500+ publishers |
| Mistral | 1 deal — AFP (Agence France-Presse) |
Sources: Press Gazette, Digiday, BuzzStream, company announcements. 2023–March 2026.
BuzzStream's analysis of top sites appearing in ChatGPT found little correlation between having a licensing deal and frequency of AI citations. OpenAI partners broadly, but partnerships don't guarantee ChatGPT will surface that publisher's content in responses. The deal secures access and compensation — it doesn't guarantee visibility.
Google's Structural Exception
Every other major AI platform operates separate crawlers for search and training. OpenAI runs GPTBot for model training and OAI-SearchBot for retrieval. Anthropic runs ClaudeBot for training. Google does not. Googlebot serves both purposes — the same crawler that indexes pages for Search also extracts content for AI Overviews, AI Mode, and Gemini. Publishers have no technical mechanism to allow Googlebot for SEO while blocking it for AI training. The choice is binary: let Google extract everything, or block Google entirely and disappear from search.
Unlike other AI companies, Google can do this because of its dominance in search: blocking Googlebot would negatively impact a website's ranking in Google's search index, which is essential for driving human traffic to websites.
This is not an engineering necessity — it is a structural coercion. Google could separate its crawlers, as its competitors have. It chooses not to. The result is that Google extracts from virtually every publisher via Googlebot — and licenses from almost none. The Associated Press is the only publisher with a confirmed deal covering LLM training data for Google's AI products. The December 2025 pilot program with The Guardian, Washington Post, and others is a non-training arrangement covering AI article overviews in Google News. This is the structural gap at the centre of the CMA's investigation.
Two Deal Models — Different Risk Profiles
Publisher receives a flat multi-year fee in exchange for broad content access rights. OpenAI's dominant approach with The Guardian, Axios, and others. Provides revenue certainty but misaligns incentives: the AI company has paid once and can consume indefinitely. People Inc. CEO Neil Vogel: "We are very happy with either model — both can be viable as long as our content is respected and paid for."
An "a la carte" marketplace where publishers set prices and AI companies pay per consumption event. The AP, USA Today Co., and People Inc. are participants. Prorata's Gist.ai runs a 50% revenue-share model across 500+ publishers, distributing revenue proportionally to how much each publisher's content drove AI responses. We believe a revenue sharing model better aligns economic value with content consumption — and creates the architecture for a functioning market.
Four Industry Initiatives Forcing Payment
Beyond bilateral deals, publishers are forming collective structures to create negotiating leverage — and to address the transparency gap that makes individual licensing unenforceable at scale.
"Voluntary transparency commitments alone are unlikely to deliver the level of disclosure needed to support licensing and enforcement." — Eilidh Wilson, Head of Policy & Public Affairs, PPA. Without knowing which content was consumed, when, and by which model, publishers cannot price, enforce, or audit licensing agreements. The entire market depends on solving this first.
The Legal Landscape
New York Times v. OpenAI remains the most-watched AI copyright case, with discovery proceedings continuing through Q1 2026. The outcome will likely establish precedent for whether training on publicly available web content constitutes fair use — a determination that could reshape the entire licensing market. Meanwhile, the EU AI Act's transparency obligations began taking effect in Q1 2026, requiring AI companies to document training data sources. This is not yet enforced at the crawler level, but it creates legal infrastructure for future accountability.
Major platforms are also drawing harder lines. Reddit restricted AI crawler access to its API and user-generated content, licensing data selectively. X/Twitter blocked bulk crawling for training purposes while allowing search indexing. LinkedIn updated its robots.txt to explicitly prohibit AI training crawlers. These platform-level decisions create precedents that publishers are watching closely.
Founded by the Financial Times, The Guardian, The Telegraph, BBC and Sky News. Aims to stop publisher content being used without permission or compensation, while creating a shared industry position rather than a fragmented response. Open to publishers of all sizes.
Publishers' Licensing Services + Copyright Licensing Agency. Aggregates content across magazines, digital news, books and academic publishing into a single repository, negotiating with AI platforms at scale. Open to any publisher with an ISSN.
A technical specification that defines how AI systems interact with publisher content at the protocol level. Sets a standardised framework for agreeing commercial terms before content is crawled — making permissions and payments machine-readable and enforceable within the infrastructure itself.
Live, opt-in model built around attribution and revenue share. Publisher content is tracked at the level of output, with compensation distributed based on usage. A working example of licensing operating at scale, combining aggregated supply with technology that assigns value to each contribution.
How Bot Management Makes Deals Enforceable
Cloudflare's Bot Management infrastructure helps convert a licensing agreement from a promise into an enforced reality:
Cloudflare's verified bot catalog confirms that the crawler claiming to be, e.g., GPTBot actually resolves to OpenAI's infrastructure. Web Bot Auth extends this to cryptographic proof. Unverified bots can be blocked.
Publishers can allow, e.g., OAI-SearchBot (which drives referral traffic — the paid partner) while blocking, e.g. GPTBot (which trains models). This distinction is what makes tiered licensing viable and the IAB's Content Monetisation Protocol actionable.
Publishers get visibility into which crawlers hit which pages, at what frequency, with what intent scores. This is the consumption data needed to verify that AI companies are accessing what they contracted for — and to feed pay-per-use marketplace models like Microsoft's.
The ability to credibly withhold content is what gives publisher leverage. Cloudflare's enforcement layer converts content into a scarce, licensable asset rather than a public good freely consumed at machine scale.
The Revenue Lag — and What Comes Next
Despite the deal velocity, publisher revenue from AI licensing remains far below what search advertising once delivered at its peak. The market is experiencing an AI licensing boom — and a revenue lag. Deals are being signed faster than revenue is materializing.
The pay-per-use marketplace model is most likely to close this gap, because it ties compensation to actual consumption at scale. But the market infrastructure — verified identity, consumption metering, access enforcement — must exist before that pricing can be trusted. Meanwhile, publishers are running out of time to wait for legislation. The UK stepped back from an opt-out approach in March 2026, leaving space for industry-led solutions — but also leaving the field open. Publishers will have to choose a route. The clear risk is fragmentation: different collective initiatives pulling in different directions, weakening the position of all of them.
The convergence of Web Bot Auth, AI Crawl Control, and pay-per-use marketplace models represents the technical and commercial stack needed for a functioning content economy on the Programmable Web. The infrastructure is in place. The deals are being signed. The window to shape the terms of this market — as a publisher, a developer, or an AI company — is open now.
The New Deal Is Being Written Now
The data from Q1 2026 tells a story of transition — and of opportunity. AI crawler volume is growing. So is the number of licensing deals. So is the sophistication of the tools publishers have to set terms, verify identity, attribute consumption, and enforce access. The infrastructure for a new content economy is not theoretical. It is operational.
Developers building on AI are not the enemy. They are the market. The question is whether publishers can participate in that market on fair terms — and the answer, for the first time, is yes.
Cloudflare's role in this transition is to be the infrastructure layer that makes the new model work — for both sides. Bot Management and AI Crawl Control give publishers the ability to define who accesses their content and on what terms. The /crawl endpoint gives developers efficient, compliant access to the web's content. Web Bot Auth gives everyone a cryptographic foundation for identity. The Attribution Dashboard gives publishers the evidence base to negotiate from a position of knowledge rather than assumption.
What to Watch in Q2 2026
NYT v. OpenAI discovery deadlines. If internal documents reveal training data sourcing practices, the case could accelerate publisher demands for transparency — or force settlement.
EU AI Act enforcement begins. The first compliance deadlines for transparency and data governance arrive in mid-2026. How regulators enforce training-data disclosure will determine whether the law has teeth.
xAI crawler scaling. GrokBot is still small in volume, but xAI's integration with X/Twitter's real-time content graph gives it a distribution advantage no other crawler has. If xAI begins crawling the open web at scale, it enters the top 10 quickly.
Google's CMA investigation. The UK Competition and Markets Authority is examining whether Google's combined search-AI crawler constitutes anti-competitive conduct. A preliminary finding in Q2 would be the first regulatory challenge to dual-purpose crawling.
Publisher collective action. The Copyright Clearance Center, Press Association, and PPA are all building collective licensing infrastructure. Q2 will reveal whether publishers can coordinate or fragment — and whether AI companies engage with collectives or continue bilateral deal-making.
The Programmable Web is being built. Cloudflare is building the access layer that determines whether it is built on extraction or on agreement. The terms are being written now — by publishers who block, by developers who comply, and by AI companies who are discovering that a web full of licensed, attributed, fairly compensated content is more valuable than a web of dark patterns and silent scraping.
Block strategically. License intentionally. Build on agreement. The new deal is better for everyone.